Healthy Living


It’s Good to be a Green Food

Nail it! Health Problems Fingernails Can Reveal

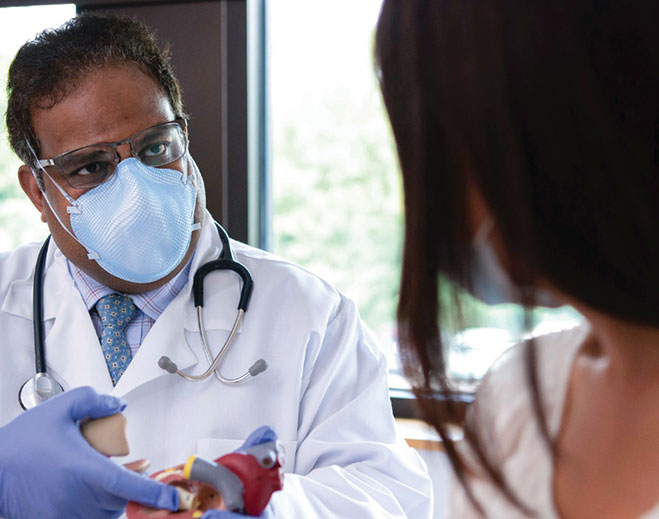
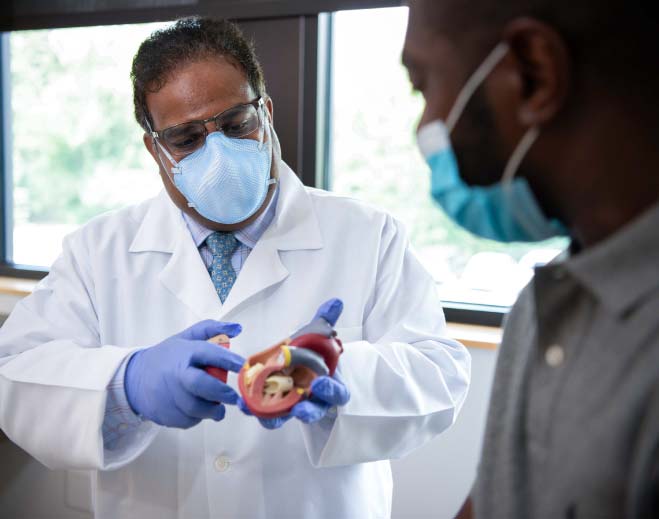
All About Heart Valves

Sleep and Your Heart: Things You Need to Know

Hypothyroidism vs Hyperthyroidism
Why Go to a Gastroenterologist?

What Is Dry Drowning?

Neck Pain and How To Get Relief
Life Hack: Simple Exercises To Help Improve Blood Pressure

Mammogram Myths Debunked

What Usually Triggers Shingles?

Is It Breast Cancer? Maybe Not.

What Does the Pancreas Do and How to Keep It Healthy
Is Your Child Eating the Right Food?

Questions to Ask Your Doctor About Weight Loss Options

Understanding Prostate Health Essentials for Men Over 40

The Benefits of Breastfeeding

Does Walking Help Lower Dementia Risk?

What is Coronary Artery Disease?

Nine Factors That Shape Bone Density
Digestive Disorders Assessment

When To See a Neurologist for Headaches?

What Does A Gynecologist Do for Menopause?

Location Clues for Headaches

General Cardiology Quiz

What Causes Fatty Liver?

Protecting Families from Heart Disease - What Causes Heart Disease?

Men's Health Concerns by the Decades

High Blood Pressure in Kids

Heimlich Maneuver on Choking Children

Women’s Health Tips for Decades | How to Stay Healthy

Learn How to Do CPR

Alone and Choking? Self-Heimlich Can Help

Dementia Signs and Prevention
.png?sfvrsn=a1e3c1df_3)
How Does Nutrition Affect the Heart?

Get To Know Your Heart Doctors

Asthma Could Raise Your Risk for Heart Disease

Myths vs. Facts About Colon Cancer

Pump It Up: Understanding Cardiac Metabolism

When You Eat Can Affect Weight and Diabetes

Maintaining Normal Blood Pressure Long Term May Lower Dementia Risk

Elbow Pain: Common Causes and Treatments

Heart Murmur Symptoms: Do You Have Them?

What is the Difference Between ADD and ADHD?

10 Health Tips for People Who Sit for Long Hours
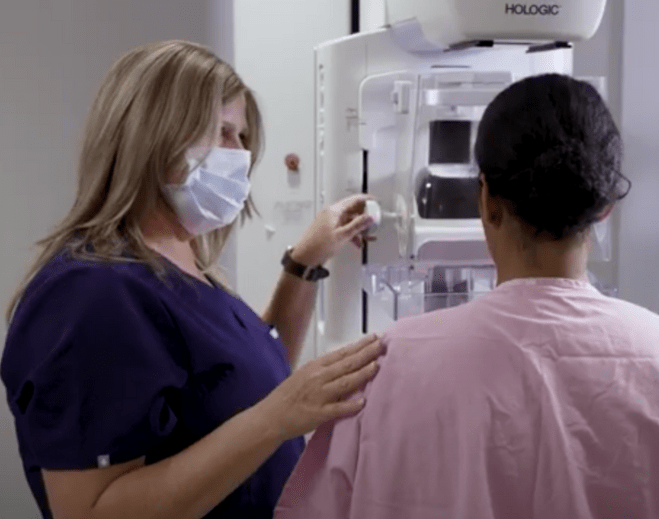
Make Time for Your Mammogram
7 Types of Rehabilitation Therapy

The Golden Rules of Driving Near Schools

A Gut Reaction: How the Gut Affects Your Health

What to Know About Atrial Fibrillation

Understanding the Highs and Lows of Testosterone

What Is Metabolic Syndrome?

Be a Superhero and Fight Off Heart Disease

Make Movement Your Mission with Brisk Walking

When to Go to the ER for Spider Bites

Recipe – Caramel Kettle Popcorn

Recipe – Energy Bars

Recipe – Ants on a Log Variations

Recipe – Peach Mango Italian Ice with Vanilla Frozen Yogurt

Dance the Day (or Night) Away!

Eight Things To Know About Sweat

Six Tips for Good Gut Health

The Allure of the Avocado

Recipe: Italian Caprese Avocado Toast

6 Things You Need to Know to Have a Healthy Pregnancy

Owning a Pet May Be Good for Your Heart

40 Reasons To Go the Full 40

Getting to Know Your Baby

Postpartum Care For You and Your Baby
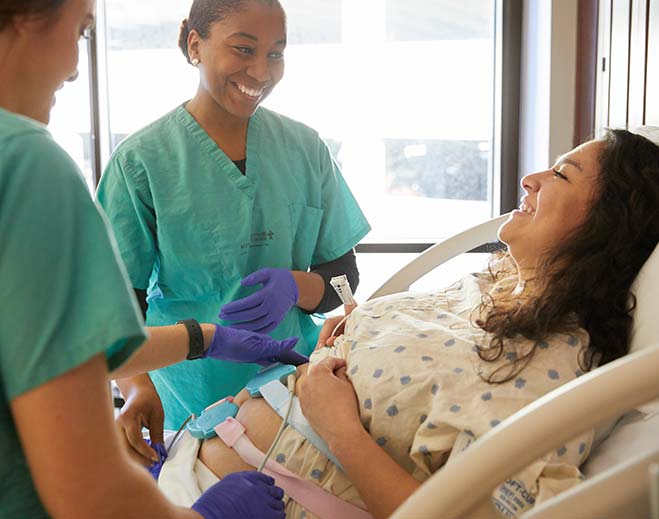
It's Go Time! Understanding the A-Z's of Labor and Delivery
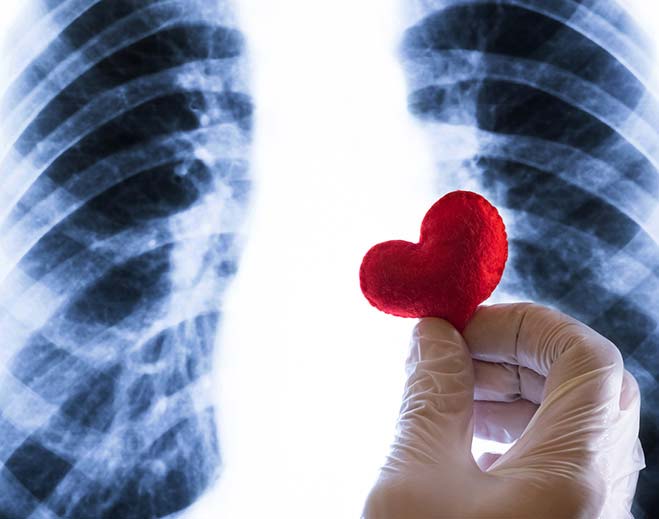
Your Heart and Inflammation

Tummy Trouble and Parkinson's Disease?

Preparing for Your Newborn

Six Pregnancy Myths Debunked
High-Risk Pregnancy Facts and Figures

What to Know About Breastfeeding Before Baby is Born

What to Expect in Your Third Trimester

What to Expect in Your Second Trimester

COVID-19 and Pregnancy

What to Expect During Your First Trimester

Healthy Eating During Pregnancy

The Tale of Kale

How to Evaluate Nutrition Facts Labels

What Causes Back Pain During Pregnancy?

Endometriosis Symptoms and Tests

Recipe: Kale and Red Quinoa Soup

Three Types of Colorectal Cancer Screenings

Top 10 Exercise Trends for 2022

Nutrition and Exercise During Pregnancy

Gestational Diabetes - What It Means and What You Can Do About It

Five Ways to Reduce Salt in Your Diet

For the Win, Eat Pumpkin

Six Steps to Reset Your Sleep Schedule

11 Common Symptoms of Pneumonia in Kids
How Thyroid Affects Everything
Seven Ways to Take Care of Your Mental Health

How to Jump Start Resolutions for Your Health

What Are Autoimmune Diseases?

Five Facts About Sugar, Your Heart and What To Do

Pepper Up, People! Here's Why.

Dislocation and Treatments

4 Types of Angina (Chest Pain)

Weight Loss and Type 2 Diabetes

Women Have a Higher Risk of Stroke

What to Expect After Knee Surgery

Gout and Sugar

10 Comfort Food Swaps for a Healthier Heart

10 Signs and Symptoms of ADHD in Adults

Recipe: Zucchini-Parmesan Pancakes

Know the Difference: Cardiac Arrest vs. Heart Attack

Recipe: Ginger Pumpkin Soup

Eat This, Not That: Foods to Fight Breast Cancer

Why Is My Ankle Hurting?

Most Recent Prescription for Cholesterol

Symptoms and Early Signs of Breast Cancer

Breast Cancer Risk Factors

The Bare Bones of Osteoporosis

What Is Respiratory Syncytial Virus (RSV) in Children?

What Do Growing Pains Mean?

Are You A Having Hormonal Imbalance?
Why Does My Knee Hurt?

Losing Weight to Gain Heart Function

Perimenopause vs. Menopause

When Does Bleeding Need Emergency Care?

Pelvic Pain in Women: Causes and How to Get Relief

Recipe: Iced Coffee Frappe

Lactation Cookie Recipe

Seven Stretches to Relax the Back

Recipe: Mixed Berry Popsicles

Bladder Leakage After Childbirth

Zucchini and Pesto Spaghetti

Low Blood Pressure: What Is It and How to Manage It

10 Cool Tips for Summer Heat

Recipe: Grilled Lemon-Garlic Chicken with Grilled Okra

Blueberries: Why Are They Healthy?

Recipe: Cottage Cheese Very Blueberry Pancakes

Heart Rate vs. Blood Pressure: What You Need to Know

How to Take Care of Your Child's Teeth
White Blood Cell Count: What You Need to Know

Life Hacks to Prevent Five Common Types of Injuries
Returning to Normal After Pandemic: Tips to Reduce Anxiety

Top 7 Health Screenings for Men

A Common Cause of Knee and Hip Pain and How to Treat It
Five Myths About Knee Replacement Surgery

13 Common COPD Symptoms

What Is Pulmonary Hypertension?

AFib: Causes, Symptoms, Treatments and Reducing Your Risk

How to Help a Baby with Constipation

Minimally Invasive Partial Knee Replacement

Seven Risks and Four Signs of a Stress Fracture

7 Key Benefits of Robotic Surgery

What Does Stress Do to Your Body?

Kidney Disease Risks, Symptoms and Prevention

5 Things to Ask When Choosing Where to Have Your Baby

What Is an Enlarged Heart?

Colorectal Cancer Trending Younger
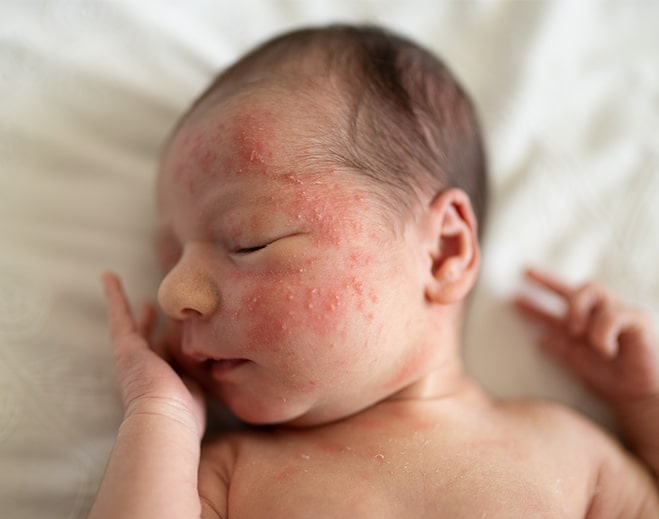
How to Get Rid of Baby Acne
Concussions in Kids
Sporting an Injury? When to See a Sports Medicine Doctor
Kidney Pain Emergencies

Ways to Avoid Valley Fever in Arizona

Simple Chicken Pot Pie

A Healthy Heart is Your Best Defense

8 Common Signs of Ear Infection in Babies

Chest Pain in Children

Top 5 Sleeping Positions for Back Pain

The Trouble with Triple A

Beware: Eight Valentine’s Day Emergencies

Five Patient Safety Tips When Visiting the Hospital
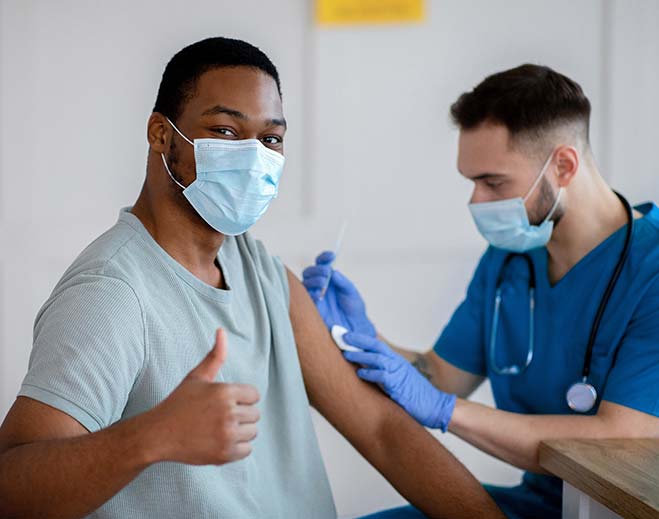
American Heart Association Supports COVID-19 Vaccines
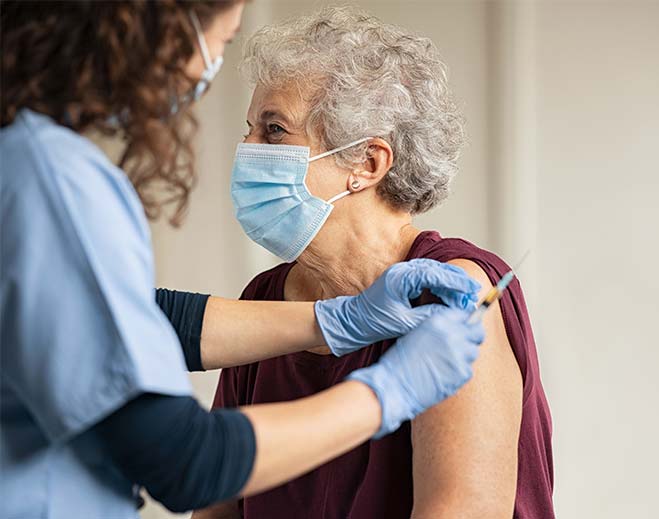
How COVID-19 Vaccines Work

What to Know About Cervical Cancer

Eight Types of Bacterial Infections and Their Symptoms

Signs of Dehydration in Adults, Infants and Young Children
Ten Questions About the COVID-19 Vaccine and What to Expect When You Get Vaccinated

Of All the Nerve! Sciatica – What It Is, How to Treat It

What to Do When Your Heart Skips a Beat

What to Know About Osteoporosis

Living With a Herniated Disc

Stretching Exercises for Your Joints

The Problem with Iron Deficiency Anemia

Do I Need Cardiac Rehab?

Have Gum Disease, Will Travel… Possibly to your Heart

How to be Good to Your Heart During the Holidays

Holidays: Better Safe than COVID

A Cornucopia of Thanksgiving Recipes

Get the Skinny on Skin Care

Five Ways to Stop Prediabetes in its Tracks

What is Congestive Heart Failure?

Get sleep. Be well.

Common Sleep Disorders

Does Your Child Have the Flu or COVID-19?

Common Knee Injuries

How Weight Affects Your Joints
10 Tips That Can Help You Start Exercising

Cold, Flu or COVID-19?

Nine Common Signs of Appendicitis

Can You Prevent Sudden Cardiac Arrest?

Infographic: Nine Tips to Strengthen Your Immunity

What Parents Need to Know about Sudden Infant Death Syndrome (SIDS)

7 Common Home Workout Injuries and How to Prevent Them
How the Census Affects Your Healthcare

Seven Ways to Prevent Sprains and Strains

Mammogram for Breast Cancer Detection

Save Money From This Insurance Deductible Tip

Is It the Flu or COVID-19?

5 Back Pain Emergencies

8 Ways to Improve Brain Health

11 Joint Pain Do's and Don'ts
Hispanics and Heart Disease

5 Surprising Reasons for an ER Visit

11 Ways to Prevent Hip Fractures

What is Multisystem Inflammatory Syndrome in Children?

10 Ways to Help Children Eat Healthy
Health Numbers That Matter
Watch Out for Gallstones and Six Other Abdominal Emergencies

Five Painful Causes of Hamstring Injury

Nine Surprising Ways to Defy Age

Is 10,000 Steps a Day Necessary?
Four Reasons to Keep Heart Arrhythmia in Check

Annual Health Screenings
Uncovering Burns: What to Know and When to Call 911
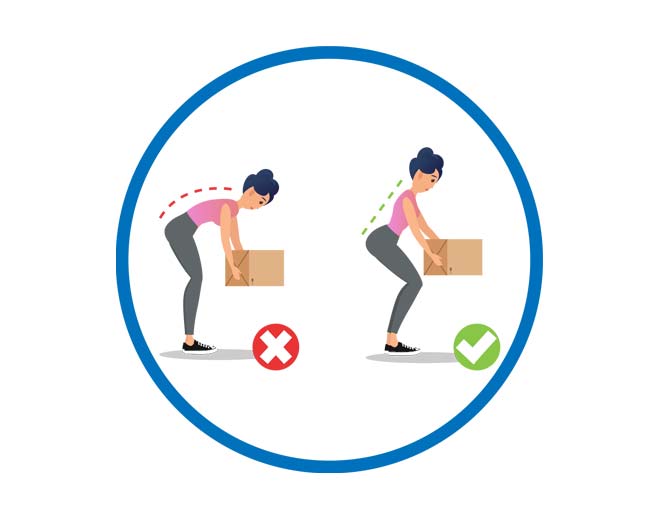
12 Ways to Prevent Lower Back Pain

Walking and Sports - What Could Happen?

ER vs. Urgent Care

Is it safe to go to the ER?

Spiders, Snakes and Bugs That Bite

Do's and Don'ts of Saving Money While Eating Healthy

Nine Heart Attack Symptoms
The Effects of Heat on Your Heart

When Is it Time to Have Weight Loss Surgery?

10 Ways to Prevent Skin Cancer
How to Beat the Heat and Celebrate Safely

How to Know if Your Child or Infant has Eye Problems

8 Warning Signs of Stress in Children

Eye Conditions that Require Emergency Care

5 Common Inherited Health Conditions and Their Symptoms

10 Most Common Health Conditions in Men

Six Tips for Social Distancing with Kids

What to Expect on a Telehealth Appointment
Navigating Healthcare and Keeping You Safe

COVID-19 Risks for People with Heart Disease and Diabetes

14 Emergencies that Require an ER

Answering Telehealth and COVID-19 Health Insurance Questions

Nine Ways to Strengthen Your Immune System

Questions and Answers About COVID-19

How Germs Are Spread and How to Prevent Them

Practicing Social Distancing

Five Apps for Help with Joint Pain

Eye Conditions and Heart Issues: The Connections

Video: Defibrillators save lives

7 Types of Foods That May Help You Prevent Colon Cancer

How to Prevent Common Brain Injuries

How to Help Your Kids Keep a Healthy Sleeping Routine

Recipe: Rustic Italian Tomato Soup

Steps for Making Weight Loss Surgery Affordable

9 Questions to Ask Your Doctor About Weight Loss Surgery

Seven Steps to Weight Loss Surgery

Maintaining Weight Loss After Surgery

Importance of Support After Weight Loss Surgery

What to Expect After Weight Loss Surgery

Eating After Weight Loss Surgery

Better Health with Weight Loss Surgery
Weight Loss Surgery Myths vs. Facts
Why Weight Loss Surgery

Four Popular Diets, De-Coded

Is Coffee Good for You?

Caregivers' Guide: Poison Prevention & Child Safety

Tips for Healthy Holiday Travel with Kids

What’s the Big Hairy Deal with Movember?

Men’s Health Maintenance Checklist

Medicare Open Enrollment Made Easier

Six Tips for Keeping Kids Healthy While You’re Sick

Prevent Sports Injuries with These Seven Tips

Separating Fact from Fiction About Cholesterol
Find a Pediatrician with Answers to These 10 Questions

Healthy Meals for Busy Lives
.jpg?sfvrsn=b08cf2fa_3)
Signs of Heat Illness

Recipe: Peanut Butter Banana Protein Bars

What Parents Need to Know About Vaping

Five Tips to Protect Your Eyes from the Sun

Recipe: Fresh Fruit Kabobs
.jpg?sfvrsn=fc25af61_1)
Food Allergies in Children

11 Tips for Water Safety
.jpg?sfvrsn=df0d4438_3)
Helping Your Children Manage Their Asthma
Salmon with Mango and Avocado Salsa

10 Ways to Improve Brain Health
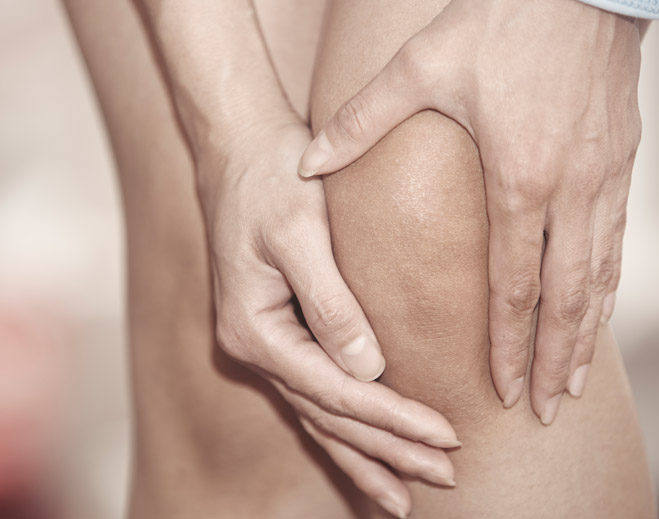
Types of Pain and How to Get Relief
Safe and Healthy Travel Tips

Why Bone Health Is Important and How to Improve It

Autism: Why Early Identification Is Important

2019 Measles Update: What Parents Should Know

Get Wiser about Getting Older
Ways to Eat Healthy and Save Money

Menopause Effects on Health

Szechuan Chicken Stir Fry

Nutrition and Your Heart: 10 Healthy Eating Tips
.jpg?sfvrsn=11209b3e_1)
Ways to Adjust to Daylight Saving Time

Teen Fainting – Should You Be Concerned?

Speech and Language Milestones
Top 10 Healthy Hints for Eating Out

When To Replace Your Athletic Shoes

Exercise Tips for Seniors
Understanding Your Pain Management Journey
Take Care of Your Family Without Getting Sick

Heart Diseases Clues by Ethnicity

Seven Signs You May Have Diabetes

Nosebleeds and How to Stop Them

Ways to Help Prepare Your Child for Surgery

Don’t Stress Your Heart Out

Apricot Glazed Baked Salmon

Stroke Is a Leading Cause of Disability
Atrial Fibrillation increases stroke risk by 5X

Sugar May Increase Risk for Heart Disease

Dementia and Heart Disease Can Be Related

Physical Fitness Lowers Heart Disease Risk

Recipe – Microwave Omelet in a Mug

Eating Breakfast Can Be Good for Your Heart...and Other Surprising Facts

Women with Diabetes Have a 40 Percent Greater Risk of Heart Disease Than Men with Diabetes

Sleeping Less Than Six Hours a Night Can Contribute to Heart Disease

Heart Disease is the No. 1 Killer of Women

You Can Control 7 of 10 Heart Disease Risks

Six Ways to Reduce High Blood Pressure

What You Gain When You Quit Smoking

Healthy Game Day Snacks

Easy Ways to Ease Into Exercise

Five Important Things To Do For Weight Loss
.jpg?sfvrsn=513dd13e_1)
Winter Coats and Car Seat Safety

Why Vitamin D Is a Big Deal

9 Ways to Lift Your Spirits During the Holidays

Help for Your Aching Back: Tips to Feel Better & When to Seek Therapy

Fresh Fruit Sangria – No Alcohol

Anytime Gifts for Caregivers

Five Tips to Stick with Your Exercise Plan in Winter

Non-Marshmallow Sweet Potato Casserole

Great Tips for Guilt-Free Holiday Eating

Gift Ideas to Keep Them Healthy

Type 2 Diabetes – Not Just for Adults

9 Fun Things to Do on Thanksgiving Day
.jpg?sfvrsn=8f2cc73e_1)
10 Ways to Reduce Stress During the Holidays

Green Bean Casserole

Six Ways to Prevent the Flu

Black Bat Bean Brownies

Memory Loss – Normal or a Concern?

Six Tips for Managing Diabetes at Thanksgiving

10 Exercises You Can Do at the Office

Enjoy this easy-to-make recipe on ‘chilly’ days or nights!

What If My Baby... ?

Newborn Reflexes: What You Need to Know

Newborn Sleep Patterns

Newborn Senses

Newborn Crying

Black Bean Brownies
.jpg?sfvrsn=61c0f73e_1)
Bullying In Children

Six Tips for A Safe Halloween

How Physical Therapy Is Key to Healing

Know What to Do to Prevent Fires and Burns

Eight Ways to Get Your Metabolism Moving
15 Ways to Boost Your Mood

Sex and Heart Disease

Long Term Effects of Sports Injuries
Roasted Cinnamon Butternut Squash

The Growing Threat of Childhood Obesity

Keeping Babies Sleeping Safe: What Moms and Dads Need to Know

What It Means to Have Sickle Cell Trait

Top 9 Health Screenings for Women

Seniors: Eight Ways to Avoid a Fall

Top 10 Health Screenings

Warning for People with Type 2 Diabetes

Seven Ways to Avoid a Fall

How Inadequate Sleep Can Affect Health

Back to School Breakfasts for Kids

Protecting Young Athletes from Sports Injuries

An Update on Alzheimer’s Disease

Pelvic Organ Prolapse: Symptoms and Treatments

Grilled Chicken Breasts with Roasted Yellow Tomato Sauce
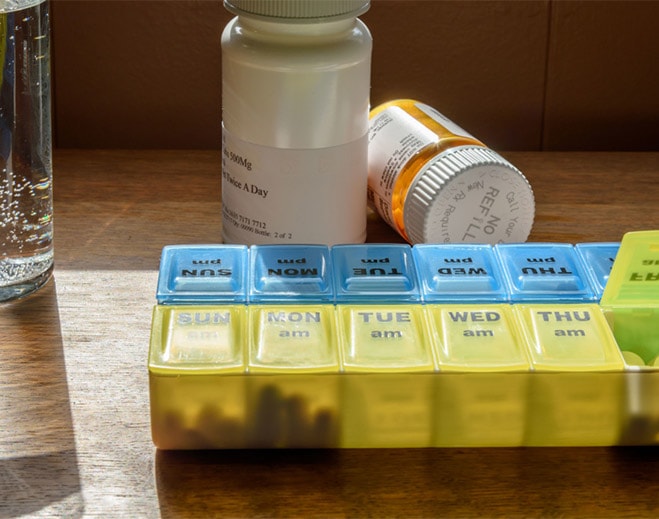
Getting Your Meds Right: Medication Reconciliation
.jpg?sfvrsn=62043a3e_3)
Concussions vs. Traumatic Brain Injury

Drink Up: Water, Hydration and Your Health

7 Ways to Have a Healthy Back-to-School Experience

Recipe: Baked Salmon with Lemon and Dill

20 Ways to Eat Healthy and Save Money

Know the Signs of Heat Illness

Preventing Eye Injuries in Kids
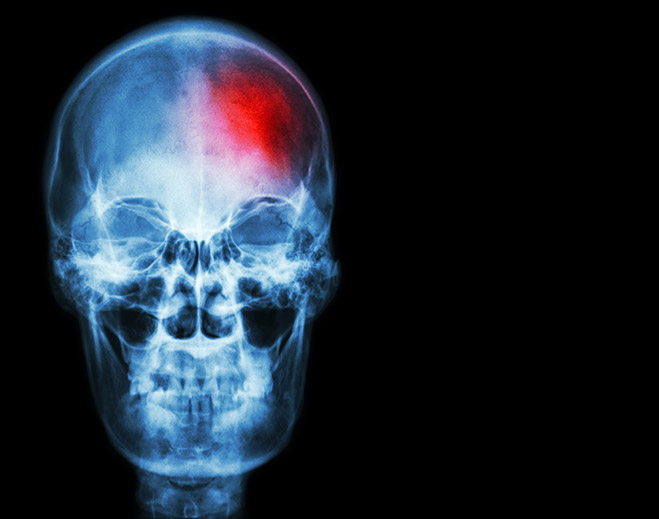
What Is a Ministroke?
.jpg?sfvrsn=4dce153e_1)
Recipe: Fruit Salad

Is Your Teen’s Headache a Migraine?

Is Your Headache a Migraine?

7 Reasons to Take a Walk

What Men Over 40 Should Know About the Prostate

Health Tips Decade By Decade

Celebrate Safely: 12 Fireworks Safety Tips

Celebrate Safely: 12 Fireworks Safety Tips for Families

High-Tech Pain in the Neck
Two for One Fitness

What to Expect in the ER
Three L’s of Lactation: Latching, Leaking, and Learning
Understanding Electrocardiograms
Complications of Diabetes: Heart Disease

What Every Woman Should Know About Menopause

Diabetes Care: Recognizing and Preventing Chronic Foot Wounds

Baby Blues vs. Post-Partum Depression

When Do You Need a Cardiac Stress Test?

What You Need to Know About Prediabetes

Summer Savvy Tips for Avoiding Illnesses

Angioplasty

Heart Disease in Women

Recipe: Yummy Guilt-Free Caesar Salad

Recipe: Berry Chia ‘Pudding’ Parfait
Valve Disease: Six Questions to Ask Your Doctor
Heart Failure and Lifestyle Changes

What is Calcium Scoring?

Arrhythmia Treatment
Five Easy Ways to Add Steps to Your Day

Peripheral Vascular Disease: “It only hurts when I walk.”
What is Heart Failure?

Get Skin Smart: Protect Yourself from the Sun
Heart Arrhythmia

Recipe: Spicy Tuna

Recipe: Turkey Scrambler Pita

Baked Sweet Potato Fries

Recipe: Slow Cooker Chicken Stew
Recipe: Mini Meatloaves

Recipe: Good Morning Sunshine Smoothie

Recipe: Dick’s Salt Free Seasoning

Support Groups: What You Need to Know

A Guide to Heart Screenings

Easy Pineapple Angel Food Cake

5 Great Ways to Add Vegetables to Your Diet

Gardening as Exercise
Don't Stress Out Your Heart - 4 Stress Relief Tips

8 Ways to Knock Out Insomnia

Helping Your Children Win the Seasonal Allergy Battle

Winning the Seasonal Allergy Battle
Don't Shrug Off Shoulder Pain

9 Everyday Hazards for Young Children

Best Moves for Strong Knees

Changing the Problem With Your Posture

7 Ways to Break the Distracted Driving Habit
How to Help Your Teen Break the Distracted Driving Habit

Scoliosis Information for Parents

Starting an Exercise Plan
Can You Prevent Cancer?

How to Have a Poison-Safe Home

Minestrone Soup Recipe
Get Early Cancer Screening Programs for Prevention

Childproofing Your Home

Poison Alert: Laundry Detergent Pods

When Is Your Flu Severe Enough to Go to the ER?

Child Health Concerns: Taking the Fear Out of a Fever

Pediatric Questions: What Shots Does My Baby Need?
What You Need to Know About Statins

What Is Bariatric Surgery?
Weight Control Strategy

High Triglyceride Levels

Requirements for Weight Loss Surgery

Joint Replacement Surgery – What You Need to Know

Discectomy for Back Pain

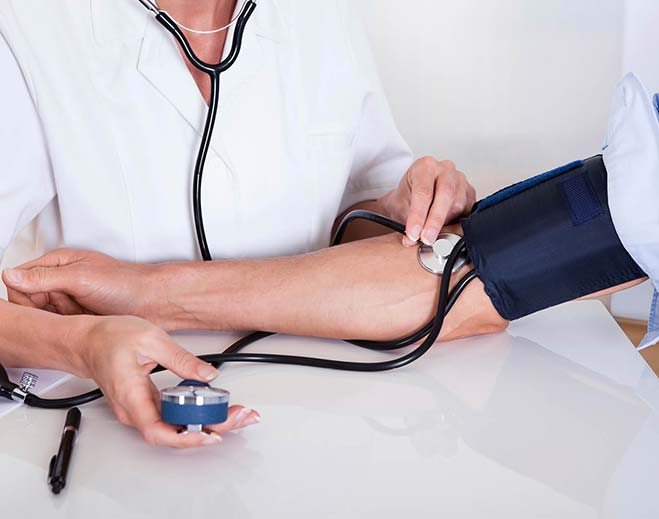
Decoding Blood Pressure Numbers
12 Foods to Avoid in Pregnancy
6 Things Your Doctor May Ask You to Do Before Hip or Knee Surgery

10 Tips to Help Fight Morning Sickness
Weight Loss Surgery Options: Dealing With Family and Friends
Symptoms of a Stroke
How to Avoid Carbon Monoxide Poisoning

Child Burn Prevention

Medical Emergencies - Teens and Inhalants

Signs of Appendicitis

What to Do in Case of a Medical Emergency

Do I Need Urgent Care or ER?
Five Scams to Avoid on the Way to a Healthy Weight Range

Seven Benefits of Losing Weight to Avoid Obesity Health Risks

Life After Weight Loss Surgery

6 Myths about Weight Loss Surgery

Do I Qualify for Weight Loss Surgery?

Carpal Tunnel Syndrome: Tingling, Numbness and Pain
Back Pain Causes and Treatments for Osteoporosis

Arthritis Pain Relief
Exercise for Arthritis

Six Ways You’re Making Knee Pain Worse

Minimally Invasive Hip Replacement

Pregnancy Exercises and More: Staying Fit in Pregnancy

Complications Giving Birth – Levels of NICU
Labor and Giving Birth: C-Sections

High Risk Pregnancy: Four Questions for Your Doctor

Risks of Pregnancy Over 35

Screening for Pregnancy Risks Over Age 35
Reducing or Managing Risks for Pregnancy Over Age 35

Coming Face-to-Face With Infertility
Cholesterol’s Role to Prevent and Reverse Heart Disease
Early Warning Signs of a Heart Attack

4 Heart Health Tips

Enjoying a Heart Health Diet


Sign Up for Health Tips
Get our advice and upcoming events about weight, pain, heart and more.
